Pour faire simple, le machine learning est une branche de l'intelligence artificielle qui permet à un ordinateur d'apprendre à partir de données, sans avoir besoin de lui dicter chaque instruction. Au lieu de suivre un code rigide, la machine identifie des schémas et s'améliore toute seule avec le temps. Un peu comme un humain qui apprend de ses expériences.
Comprendre le machine learning avec une analogie simple
Oublions un instant les algorithmes et le jargon technique. L'image la plus parlante est celle d'un enfant qui apprend à faire la différence entre un chat et un chien.
Vous n'allez pas lui donner une liste de règles strictes du genre : "Si ça a des oreilles pointues, des moustaches et que ça miaule, alors c'est un chat". Cette méthode serait bien trop limitée et échouerait face à la diversité des races de chats.
L'apprentissage par l'exemple, le cœur du réacteur
À la place, vous lui montrez des dizaines, puis des centaines de photos en disant : "Ça, c'est un chat" ou "Là, c'est un chien". Progressivement, son cerveau commence à repérer des points communs, des motifs récurrents, même sans pouvoir mettre des mots dessus.
Après avoir vu assez d'exemples, il devient capable de reconnaître un chat qu'il n'a jamais vu auparavant. Il n'a pas mémorisé des règles, il s'est entraîné sur des données. Le machine learning, c'est exactement ça : l'apprentissage par l'expérience à grande échelle.
L'idée n'est pas de programmer la réponse, mais de construire un système capable de trouver la réponse par lui-même en analysant des exemples. C'est ce qui change tout par rapport à la programmation classique.
Pour bien voir la différence fondamentale, ce petit tableau est très parlant.
Comparaison entre programmation traditionnelle et machine learning
Ce tableau met en évidence les différences fondamentales entre une approche de programmation classique et une approche basée sur le machine learning pour résoudre un problème.
| Critère | Programmation traditionnelle | Machine learning |
|---|---|---|
| Approche | Le développeur écrit des règles explicites (logique "si… alors…") pour traiter les données. | Le système apprend les règles lui-même à partir des données fournies. |
| Logique | Déterministe : pour les mêmes entrées, on a toujours les mêmes sorties. | Probabiliste : le système fait des prédictions basées sur ce qu'il a appris. |
| Données | Les données sont l'entrée que le programme traite. | Les données sont le carburant pour entraîner le modèle. |
| Résultat | Un programme exécutable qui suit des instructions. | Un modèle entraîné capable de faire des prédictions sur de nouvelles données. |
| Adaptabilité | Faible. Chaque nouvelle règle doit être codée manuellement par un humain. | Élevée. Le modèle peut s'améliorer et s'adapter en continu avec de nouvelles données. |
On voit bien que les deux approches sont radicalement différentes. L'une suit des ordres, l'autre apprend de l'expérience.
Cette infographie illustre parfaitement ce processus en trois étapes clés, des données initiales jusqu'à la prédiction.
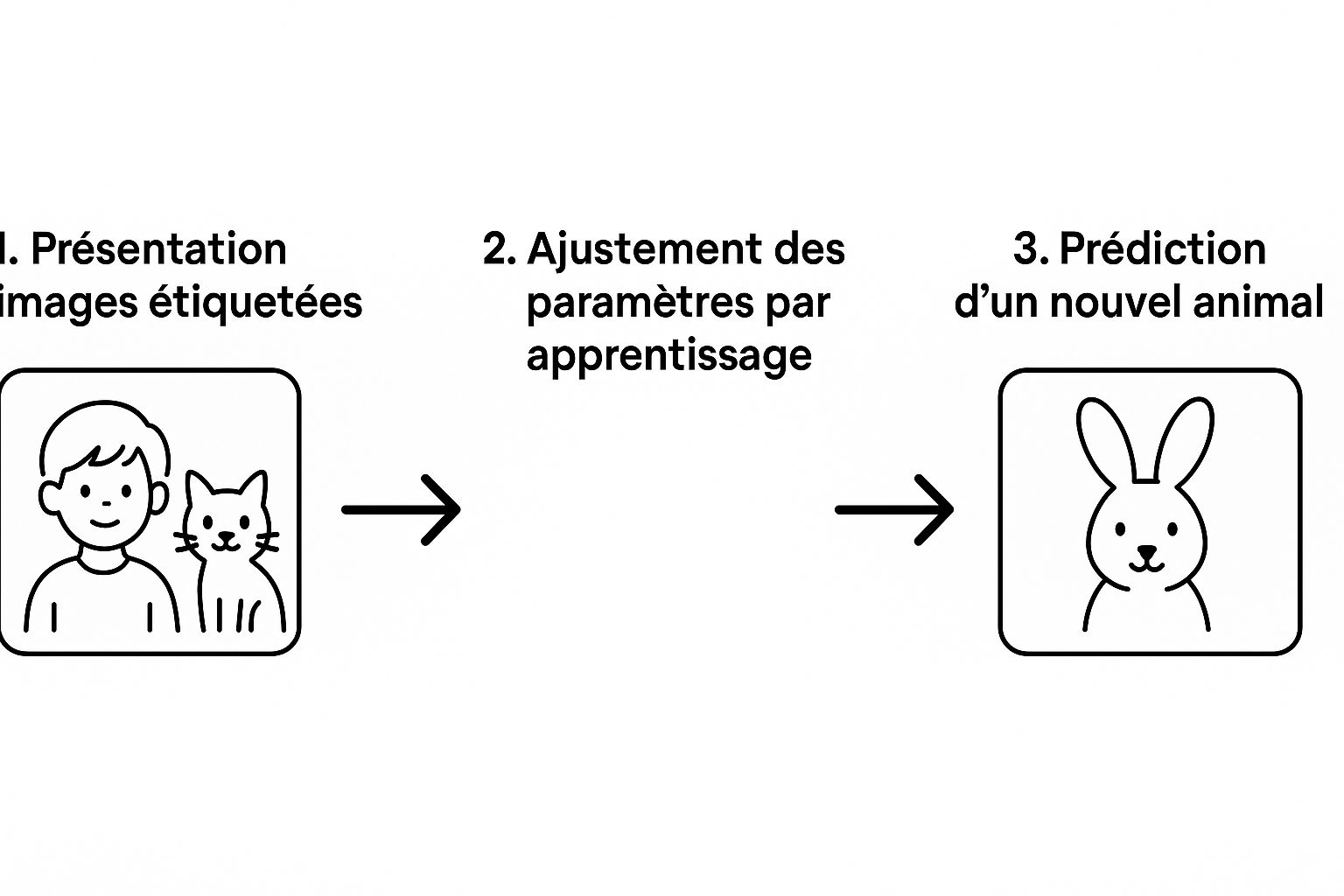
Le diagramme montre bien comment le système ajuste ses propres "boutons" internes en fonction des exemples, ce qui lui permet ensuite d'identifier correctement une image qu'il n'a jamais vue.
Une idée qui ne date pas d'hier
Même si le terme est sur toutes les lèvres aujourd'hui, le concept est bien plus ancien qu'on ne le pense. Dès 1959, l'informaticien américain Arthur Samuel avait créé un programme qui jouait aux dames et, surtout, qui améliorait son jeu après chaque partie. L'idée a ensuite fait son chemin, en s'appuyant sur les statistiques et la reconnaissance de formes.
Le principe de base n'a pas changé :
- Fournir des données en entrée : On "nourrit" le modèle avec un grand volume de données pertinentes (des images, des chiffres de vente, des avis clients…).
- Lancer la phase d'entraînement : On laisse l'algorithme analyser ces données pour dénicher des corrélations et des schémas invisibles à l'œil nu.
- Obtenir un modèle prédictif : Le résultat est un "modèle" entraîné, prêt à faire des prédictions ou à prendre des décisions sur de toutes nouvelles données.
C'est cette capacité à transformer des informations brutes en prédictions utiles qui rend cette technologie si précieuse pour les entreprises. C'est le moteur qui se cache derrière les recommandations de produits sur Amazon, la détection de fraudes bancaires ou les prévisions météo. Un sujet que nous couvrons souvent dans notre catégorie bon à savoir.
Comment un modèle de machine learning apprend vraiment
Comprendre le concept, c'est bien. Mais voir concrètement comment une machine transforme un tas de données brutes en prédictions intelligentes, c'est encore mieux. Le processus n'a rien de magique ; il suit un parcours logique et structuré, un peu comme la recette d'un grand chef.
Et comme pour toute bonne recette, tout commence par le choix des ingrédients. En machine learning, cet ingrédient essentiel, c'est la donnée. C'est elle qui va nourrir et sculpter l'intelligence du modèle.

Étape 1 : La collecte et la préparation des données
Avant même d'écrire une seule ligne de code, la première étape, et de loin la plus cruciale, consiste à réunir les bonnes données. Si vous êtes un e-commerçant qui veut anticiper ses prochaines ventes, il vous faudra rassembler l'historique des transactions, les infos sur vos produits et les données de navigation de vos clients.
Mais attention, les données brutes sont rarement utilisables telles quelles. Elles sont souvent incomplètes, truffées d'erreurs ou d'incohérences. La phase de nettoyage est donc absolument fondamentale. Il s'agit de corriger les anomalies, de combler les trous et de s'assurer que les données sont fiables.
Un modèle de machine learning, aussi puissant soit-il, ne pourra jamais compenser des données de mauvaise qualité. C'est le fameux principe du "Garbage In, Garbage Out" : si vous lui donnez des ordures à manger, il vous sortira des ordures.
Ce travail de préparation peut engloutir jusqu'à 80 % du temps total d'un projet. C'est fastidieux, mais c'est le prix à payer pour obtenir des résultats pertinents. Bien sûr, il est aussi vital de bien protéger ces données ; vous pouvez d'ailleurs en apprendre plus pour ne pas prendre le risque de perdre vos données dans un incendie ou une cyberattaque.
Étape 2 : Le choix du bon algorithme
Une fois que vos données sont propres et prêtes à l'emploi, il faut choisir le bon outil pour les analyser. L'algorithme, c'est un peu la méthode de cuisson que le modèle va suivre pour apprendre. Il en existe des centaines, chacun avec ses forces, ses faiblesses, et adapté à des problèmes bien spécifiques.
Choisir le bon algorithme, c'est comme un artisan qui sélectionne l'outil parfait pour sa tâche :
- Pour trier des e-mails en "spam" ou "non spam", on se tournera vers un algorithme de classification comme la régression logistique.
- Pour estimer le prix d'un appartement, un algorithme de régression comme les forêts aléatoires (random forests) sera plus indiqué.
- Pour regrouper des clients en segments homogènes, des algorithmes de clustering comme K-Means feront merveille.
Le choix dépend entièrement de votre objectif. Que voulez-vous accomplir ? La réponse à cette question dictera l'outil à utiliser.
Étape 3 : L'entraînement du modèle
C'est là que la "magie" opère. On présente les données préparées à l'algorithme choisi. Le modèle va alors les mouliner, encore et encore, pour déceler des schémas, des relations cachées et des corrélations.
Imaginez un sculpteur qui, à chaque coup de ciseau, affine son geste pour se rapprocher de la statue qu'il a en tête. Le modèle fait pareil : il ajuste ses paramètres internes petit à petit pour réduire son "erreur" de prédiction. Il compare sans cesse ses résultats avec les vraies réponses (celles de vos données) et se corrige jusqu'à atteindre un niveau de précision acceptable.
Étape 4 : L'évaluation et l'ajustement
Attention, un modèle qui obtient un 20/20 sur ses données d'entraînement n'est pas forcément un bon élève. Il pourrait simplement avoir "appris par cœur" sans vraiment comprendre la logique de fond. C'est ce qu'on appelle le surapprentissage (overfitting).
Pour déjouer ce piège, on le teste sur un jeu de données qu'il n'a jamais vu. C'est son examen final. S'il s'en sort bien, c'est qu'il a su "généraliser" ce qu'il a appris et qu'il est prêt pour le monde réel. Sinon, on retourne à l'atelier pour l'ajuster.
Étape 5 : Le déploiement et le suivi
Une fois validé, le modèle est prêt à être mis en service. On l'intègre dans un environnement de production pour qu'il commence à créer de la valeur : un système de recommandation sur votre site e-commerce, un outil de détection de fraude, un tableau de bord prédictif…
Mais le travail ne s'arrête pas là. Le monde bouge, les habitudes de vos clients changent, et les performances du modèle peuvent se dégrader avec le temps. Un suivi constant est donc indispensable pour s'assurer qu'il reste pertinent et, si besoin, le ré-entraîner avec de nouvelles données fraîches.
Les trois grandes approches du machine learning
Le terme "machine learning" est un peu comme le mot "véhicule" : il peut désigner une voiture, un vélo ou un camion. Derrière ce nom se cachent en réalité plusieurs familles d'algorithmes, chacune conçue pour résoudre des problèmes très différents.
Comprendre ces grandes approches est la première étape pour voir comment cette technologie peut concrètement vous aider. On distingue principalement trois catégories : l'apprentissage supervisé, non supervisé et par renforcement. Chacune a sa propre logique, ses points forts et ses applications de prédilection.

L'apprentissage supervisé : l'élève et son corrigé
De loin l'approche la plus répandue, l'apprentissage supervisé est aussi la plus intuitive. Le principe est simple : on entraîne l'algorithme avec des données qui ont déjà été "étiquetées" par un humain. C'est comme donner à un étudiant un livre d'exercices avec les corrigés à la fin.
En analysant des milliers d'exemples où la bonne réponse est déjà connue, le modèle apprend à faire le lien entre les données qu'on lui donne et le résultat attendu. Il finit par repérer les motifs récurrents qui mènent à une étiquette précise.
Cette méthode se décline en deux types de missions :
-
La classification : L'objectif est de ranger une donnée dans une case. Cet e-mail est-il un "spam" ou "non spam" ? Ce client est-il susceptible de "résilier" ou de "rester" ? Le modèle apprend à trier.
-
La régression : Ici, on cherche à prédire une valeur numérique. Quel sera le prix de cette maison en fonction de sa surface ? Quel sera le chiffre d'affaires du prochain trimestre ? Le modèle apprend à estimer un nombre.
L'apprentissage supervisé est parfait quand vous avez un objectif clair et que vous possédez des données historiques où le résultat que vous cherchez à prédire est déjà présent.
Cette approche est redoutablement efficace pour des applications très concrètes dans une PME. Pensez à la prédiction de la demande pour mieux gérer vos stocks ou à l'identification des prospects les plus prometteurs dans votre fichier clients.
L'apprentissage non supervisé : le détective des données
Maintenant, imaginez donner à votre modèle une montagne de données brutes, sans aucune étiquette ni corrigé. C'est ça, l'apprentissage non supervisé. La machine doit se débrouiller seule pour y trouver une structure, des groupes ou des anomalies cachées.
Elle se comporte comme un détective qui, face à une pile de documents en vrac, commencerait à les regrouper par similarités pour y déceler des schémas logiques.
Les deux applications les plus courantes sont :
-
Le clustering (ou segmentation) : L'algorithme regroupe les données en "clusters" homogènes. C'est l'idéal pour segmenter votre base clients en groupes distincts (par exemple, les "clients fidèles à petit panier" ou les "nouveaux à fort potentiel") et ainsi personnaliser vos campagnes marketing.
-
La détection d'anomalies : Le modèle apprend à quoi ressemble une situation "normale" et vous alerte dès que quelque chose sort de ce cadre. C'est la technique utilisée pour repérer des transactions bancaires frauduleuses ou anticiper des pannes sur une machine industrielle.
Cette méthode est particulièrement précieuse quand vous ne savez pas exactement ce que vous cherchez, mais que vous êtes convaincu que vos données ont des choses à vous dire.
L'apprentissage par renforcement : l'art de la récompense
La troisième grande approche, l'apprentissage par renforcement, est radicalement différente. Ici, pas de données historiques à analyser. Le modèle apprend en direct, par essais et erreurs, dans un environnement dynamique. Il reçoit des "récompenses" quand il fait une bonne action et des "punitions" dans le cas contraire.
C'est exactement comme ça qu'on apprend à un chien à donner la patte. On ne lui montre pas 1000 photos de chiens donnant la patte. On attend qu'il tente une action ; s'il lève la bonne patte, on lui donne une friandise (la récompense). Avec le temps, il comprend quelle action mène au biscuit et la répète.
Le modèle de machine learning fonctionne pareil. Il explore différentes stratégies et ajuste son comportement pour maximiser les récompenses qu'il accumule sur le long terme.
C'est une approche très puissante pour résoudre des problèmes complexes d'optimisation où les décisions s'enchaînent.
Quelques exemples concrets :
- Logistique : Optimiser en temps réel les itinéraires d'une flotte de livraison pour minimiser la consommation de carburant.
- Robotique : Apprendre à un bras robotisé à saisir des objets de formes variées sur une chaîne de montage.
- Finance : Développer des stratégies de trading automatiques qui s'adaptent aux mouvements du marché.
Même si elle est plus complexe à mettre en place, cette méthode ouvre la voie à des automatisations très poussées, où le système apprend et affine seul la meilleure stratégie pour atteindre un objectif.
Le machine learning en France : bien plus qu’une simple tendance
Quand on parle de machine learning, l'image de la Silicon Valley vient tout de suite à l'esprit. Pourtant, ce serait une erreur de penser que la France ne fait que suivre le mouvement. En réalité, notre pays est l'un des berceaux historiques de cette technologie et possède aujourd'hui un écosystème incroyablement dynamique.
Loin d'être un phénomène de mode, l'intelligence artificielle a des racines profondes dans l'Hexagone. Pour les TPE et PME françaises qui cherchent à innover, cette expertise locale est un avantage stratégique majeur.
Un héritage de pionniers bien français
Bien avant que "machine learning" ne soit sur toutes les lèvres, des chercheurs français en posaient déjà les bases. Dès les années 1980, la France était à la pointe de la recherche, au carrefour des mathématiques appliquées et de l’IA naissante.
Des travaux fondateurs, comme ceux menés par le mathématicien Robert Azencott et son laboratoire DIAM, ont ouvert la voie à des techniques d'IA révolutionnaires. Et ce n’était pas que de la théorie ! Ces innovations ont très vite été mises en pratique par des fleurons industriels comme EDF, le CNES ou encore Ariane Espace. Si vous voulez saisir l'ampleur de cet héritage, il faut absolument se pencher sur les débuts de l'aventure française de l'intelligence artificielle.
Cette histoire prouve que l'expertise française n'est pas nouvelle : elle est mature, elle a fait ses preuves et elle est solidement ancrée dans notre culture scientifique et industrielle.
Pour une entreprise française, faire appel au machine learning, ce n'est pas juste adopter une technologie. C'est puiser dans un savoir-faire local, collaborer avec des talents formés dans nos meilleures écoles et bénéficier d'une compréhension intime de notre propre marché.
Un écosystème actuel riche et à portée de main
Aujourd'hui, cette excellence non seulement perdure, mais elle s'accélère. La France est le foyer de laboratoires de recherche de renommée mondiale, d'un terreau fertile de startups spécialisées en IA et d'un vivier de talents que le monde entier nous envie.
Pour une entreprise, même de petite taille, cet écosystème se traduit par des opportunités très concrètes :
- Un accès direct à l'expertise : consultants, agences, freelances… De nombreux experts français se sont spécialisés dans l'accompagnement des PME pour lancer leurs premiers projets d'IA.
- Des solutions faites pour vous : Des startups développent des outils de machine learning pensés spécifiquement pour les réalités, les besoins et les budgets des plus petites entreprises.
- Des coups de pouce financiers : L'État et les régions soutiennent activement l'adoption de ces technologies. D'ailleurs, il est souvent plus simple qu'on ne le pense d'obtenir un financement pour la transformation digitale de votre entreprise.
S'intéresser au machine learning en France, ce n'est donc pas seulement suivre une vague technologique mondiale. C'est avant tout s'appuyer sur un réseau de compétences locales, fiables et parfaitement connectées aux réalités du terrain. L'innovation n'a jamais été aussi accessible.
Des applications concrètes pour votre PME
La théorie du machine learning, c'est bien beau, mais la vraie question, c'est : qu'est-ce que ça peut changer, concrètement, pour une PME comme la vôtre ? Oubliez les fantasmes de science-fiction. Cette technologie est déjà au travail dans des milliers d'entreprises pour régler des problèmes très terre à terre, générant des gains de temps et d'argent bien réels.
Le machine learning n'est plus un luxe réservé aux géants du web. C'est devenu un levier de compétitivité accessible, capable d'automatiser des tâches qui vous plombent et d'apporter des éclairages précieux pour prendre de meilleures décisions.

Optimiser votre gestion des stocks et vos ventes
Trouver le juste équilibre pour ses stocks, c'est le casse-tête de nombreuses PME. Trop de stock ? C'est de la trésorerie qui dort et un risque d'invendus. Pas assez ? C'est la rupture assurée, avec des clients frustrés et des ventes manquées à la clé.
Le machine learning s'attaque directement à ce problème. En analysant votre historique de ventes, la saisonnalité, et même des facteurs externes comme la météo ou les vacances scolaires, un modèle peut prédire la demande future pour chaque produit avec une précision bluffante.
- Le problème : Gérer les commandes fournisseurs "au doigt mouillé", ce qui mène à des surplus ou des manques.
- La solution ML : Un algorithme qui anticipe les ventes des prochaines semaines en se basant sur vos données.
- Le bénéfice : Vous commandez les bonnes quantités au bon moment. Résultat ? Une réduction des coûts de stockage de 20 % à 30 % en moyenne et un chiffre d'affaires maximisé.
Personnaliser votre marketing pour mieux convertir
Les campagnes marketing de masse, où l'on envoie le même message à tout le monde, c'est terminé. Aujourd'hui, la clé du succès, c'est la personnalisation. Vos clients attendent des offres qui leur parlent vraiment.
Un modèle de clustering peut plonger dans les données de votre CRM (historique d'achats, fréquence, panier moyen) pour segmenter automatiquement votre clientèle en groupes cohérents. Vous pouvez alors créer des campagnes ultra-ciblées qui touchent chaque segment en plein cœur.
C'est la fin du marketing à l'aveugle. Au lieu d'espérer que votre message touche sa cible, vous vous adressez directement aux bonnes personnes, avec la bonne offre, au bon moment. L'impact sur les taux de conversion est immédiat.
Automatiser les tâches administratives qui vous rongent le temps
Combien d'heures vos équipes perdent-elles chaque semaine à saisir des factures à la main, à extraire des infos de documents ou à trier des e-mails ? Ces tâches, peu valorisantes et sources d'erreurs, sont les candidates parfaites pour l'automatisation.
Des algorithmes spécialisés peuvent littéralement "lire" une facture, en extraire les informations clés (fournisseur, montant, date) et les injecter directement dans votre logiciel comptable, sans aucune intervention manuelle.
- Le problème : La saisie manuelle de centaines de factures fournisseurs, une tâche lente et fastidieuse.
- La solution ML : Un système qui numérise, lit et traite les factures pour vous.
- Le bénéfice : Un gain de temps qui peut atteindre 80 % sur le traitement des factures. Vos équipes peuvent enfin se concentrer sur des missions qui créent vraiment de la valeur.
Anticiper les pannes pour éviter les arrêts de production
Pour une PME industrielle, l'arrêt imprévu d'une machine peut coûter une fortune. La maintenance prédictive change complètement la donne. Au lieu de réparer une fois que la panne est là, le machine learning permet de la voir venir.
Comment ? En plaçant des capteurs sur vos équipements critiques, un modèle peut analyser en continu les données de fonctionnement (vibrations, température…). Il détecte alors des signaux faibles, invisibles à l'œil nu, qui annoncent une défaillance imminente.
L'adoption de ces technologies s'accélère. En France, 10 % des entreprises d'au moins 10 salariés utilisent déjà au moins une technologie d'IA, contre 6 % l'année précédente. La taille joue un rôle : si 9 % des PME de moins de 50 salariés l'utilisent, ce chiffre monte à 15 % pour les ETI (50 à 249 salariés) et même 33 % pour les grandes entreprises. Pour creuser le sujet, vous pouvez consulter les statistiques détaillées sur l'adoption de l'IA.
On répond à vos questions sur le machine learning
Plonger dans le machine learning, ça peut paraître intimidant. Surtout quand on dirige une PME et qu'on a déjà mille autres choses à gérer. Loin du jargon technique qui noie le poisson, cette section va droit au but. On répond aux questions que vous vous posez vraiment, avec des mots simples.
L'objectif n'est pas de faire de vous un ingénieur, mais de vous donner les clés pour comprendre ce que ces technologies peuvent concrètement apporter à votre business. Pensez à ces réponses comme à une discussion franche, pour y voir plus clair et commencer à réfléchir stratégiquement.
Quelle est la différence entre IA, machine learning et deep learning ?
On entend ces trois termes partout, souvent mélangés, ce qui crée une belle pagaille. Pour y voir clair, l'image la plus simple est celle des poupées russes. C'est juste une question d'emboîtement.
Imaginez la plus grande poupée : c'est l'Intelligence Artificielle (IA). L'IA, c'est le grand concept, le rêve de créer des machines qui imitent l'intelligence humaine pour raisonner, comprendre ou planifier.
Ouvrez cette poupée. À l'intérieur, il y en a une autre, c'est le machine learning. Le machine learning est une façon d'arriver à l'IA. Au lieu de programmer des règles à la main, on laisse la machine apprendre toute seule à partir de données. C'est une branche spécifique de l'IA.
Maintenant, ouvrez cette deuxième poupée. Vous découvrez la plus petite, la plus spécialisée : le deep learning (ou apprentissage profond). C'est une technique de machine learning particulièrement puissante, qui s'inspire du cerveau humain. Elle est championne pour trouver des schémas très complexes, par exemple dans des images, des vidéos ou du son.
En résumé : tout deep learning est du machine learning, et tout machine learning est une forme d'IA. Mais l'inverse n'est pas vrai. C'est simplement une question de spécialisation.
De quelles données ai-je besoin pour commencer ?
C'est LA question qui bloque tout le monde. Beaucoup de dirigeants s'imaginent qu'il faut des montagnes de données, mais c'est une fausse idée. La qualité l'emporte toujours sur la quantité. Un petit jeu de données propres et bien rangées vaut mille fois plus qu'un océan de données en désordre.
La première chose à faire, c'est de définir le problème que vous voulez résoudre. Anticiper les pannes ? Prédire les ventes du mois prochain ? Mieux cibler vos clients ? C'est cette question qui vous dira quelles données chercher.
Et la bonne nouvelle, c'est que vous avez déjà ces données. Elles dorment tranquillement dans les outils que vous utilisez chaque jour.
- Votre CRM : C'est une mine d'or. Historiques d'achats, interactions avec vos commerciaux… Tout y est pour comprendre et anticiper le comportement de vos clients.
- Votre ERP : Il contient vos données de production, de stock, de facturation. Parfait pour optimiser votre chaîne logistique ou vos finances.
- Votre site e-commerce : Chaque clic, chaque produit vu, chaque panier abandonné est une information précieuse pour personnaliser l'expérience de vos visiteurs.
- Vos machines de production : Dans l'industrie, les données des capteurs (vibrations, température…) sont le carburant de la maintenance prédictive.
L'important, c'est de partir d'un vrai besoin métier, puis de regarder où se trouvent les données correspondantes dans votre entreprise.
Combien coûte un projet de machine learning ?
Le coût peut aller de quelques milliers d'euros pour un test simple à bien plus pour des systèmes complexes. Mais pour une PME, il est tout à fait possible de démarrer avec un budget maîtrisé.
En gros, les coûts se répartissent sur trois postes principaux : les compétences, les outils et les données.
-
Les compétences : C'est souvent le plus gros morceau. C'est le temps que les experts vont passer à préparer les données, créer le modèle et le mettre en place. Les tarifs ne sont pas les mêmes si vous passez par un freelance, une agence ou si vous formez quelqu'un en interne.
-
Les outils et l'infrastructure : L'époque où il fallait acheter des serveurs hors de prix est terminée. Aujourd'hui, avec le cloud (Amazon Web Services, Google Cloud ou Microsoft Azure), on peut "louer" de la puissance de calcul à la demande. C'est très accessible.
-
La préparation des données : Si vos données sont un peu chaotiques, il faudra prévoir un budget pour les nettoyer et les organiser. C'est une étape indispensable, un investissement non négociable pour avoir des résultats fiables.
Pour une PME, le mieux est d'y aller pas à pas. On commence par un petit projet pilote bien ciblé, avec un objectif clair et un retour sur investissement facile à mesurer. Ça permet de tester l'eau sans prendre de risque financier.
Faut-il recruter un data scientist ?
Réponse courte : non, pas forcément. Surtout au début. L'idée du data scientist de génie qui travaille seul dans son coin est un peu un mythe hollywoodien. Pour un premier projet, il existe des solutions bien plus souples.
-
Former quelqu'un en interne : Vous avez sûrement dans votre équipe une personne à l'aise avec les chiffres, qui connaît votre métier sur le bout des doigts (un contrôleur de gestion, un analyste marketing…). Lui financer une bonne formation peut être un excellent calcul à moyen terme.
-
Faire appel à un freelance : Pour une mission ponctuelle ou un projet pilote, c'est la solution la plus flexible. Un expert indépendant vous apporte la compétence technique qui vous manque pour démarrer, sans engagement sur la durée.
-
Travailler avec une agence spécialisée : Si votre projet est plus structurant ou que vous voulez un accompagnement de A à Z, une agence comme la nôtre peut vous guider de la stratégie à la mise en production.
L'essentiel, c'est de ne pas mettre la charrue avant les bœufs. Commencez petit, prouvez la valeur du machine learning sur un cas d'usage concret. Ensuite, et seulement ensuite, vous pourrez vous poser la question d'internaliser la compétence.
Le machine learning n'est plus une technologie futuriste réservée aux géants. C'est une boîte à outils concrète pour mieux performer. Chez Webintelligence, nous aidons les TPE et PME à mettre en place des solutions d'IA et d'automatisation sur mesure, en partant toujours de vos défis métier. Explorez nos services et découvrez comment nous pouvons transformer vos données en véritable avantage concurrentiel.
